https://www.sunjianbo.com孙建博的小站2021-02-18T07:52:46.385Zhttps://github.com/jpmonette/feed互联网、编程、生活感悟,在这里希望你我都能有所收获,得到提升https://www.sunjianbo.com/images/avatar.pnghttps://www.sunjianbo.com/favicon.icoAll rights reserved 2021, 孙建博的小站<![CDATA[为什么HashMap链表存储结构转换为红黑树的长度临界点是8?]]>https://www.sunjianbo.com/why-threshold-is-8/2021-02-18T07:30:10.000Z为什么HashMap链表存储结构转换为红黑树的长度临界点是8?
分布规律
概率统计学,在随机哈希代码下,链表长度超过8的概率非常非常小
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more: less than 1 in ten million
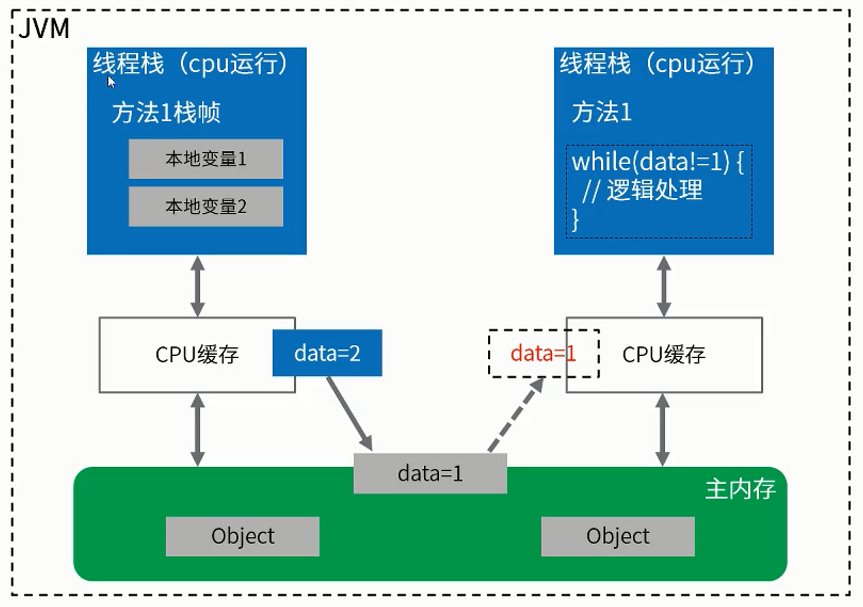
final在该对象的构造函数中设置对象的字段,当线程看到该对象时,将始终看到该对象的final字段的正确构造版本。
伪代码示例: f= new finalDemo();读取到的f.x一定最新,x为final字段。而y可能是0
// 官方示例,可能会读取到y的值为0
class FinalFieldExample {
final int x;
int y;
static FinalFieldExample f;
public FinalFieldExample() {
x = 3;
y = 4;
}
static void writer() {
f = new FinalFieldExample();
}
static void reader() {
if (f != null) {
int i = f.x; // guaranteed to see 3 肯定是3
int j = f.y; // could see 0 可能看到0
}
}
}
如果在构造函数中设置字段后发生读取,则会看到该final字段分配的值,否则它将看到默认值;
伪代码示例: public finalDemo(){x=1;y=x;};y会等于1;
读取该共享对象的final成员变量之前,先要读取共享对象。
伪代码示例:r = new ReferenceObj();k=r.f;这两个操作不能重排序
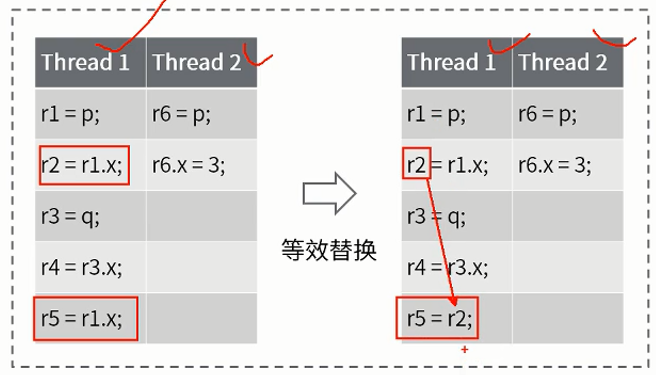
这个问题有时候被称为**“字分裂 word tearing)”**,在单独更新单个字节有难度的处理器上,就需要寻求其它方式了。
基本不需要考虑这个,了解就好。
// https://docs.oracle.com/javase/specs/jls/se8/html/jls-17.html#jls-17.4
// 官方提供的示例,检查有没有WordTearing情况
public class WordTearing extends Thread {
static final int LENGTH = 8;
static final int ITERS = 1000000;
static byte[] counts = new byte[LENGTH];
static Thread[] threads = new Thread[LENGTH];
final int id;
WordTearing(int i) {
id = i;
}
public void run() {
byte v = 0;
for (int i = 0; i < ITERS; i++) {
byte v2 = counts[id];
if (v != v2) {
System.err.println("Word-Tearing found: " +
"counts[" + id + "] = " + v2 +
", should be " + v);
return;
}
v++;
counts[id] = v;
}
}
public static void main(String[] args) {
for (int i = 0; i < LENGTH; ++i)
(threads[i] = new WordTearing(i)).start();
}
}



 )
)