
多线程中的问题
- 所见非所得
- 无法肉眼去检测程序的准确性
- 不同的运行平台有不同的表现
- 错误很难重现
问题示例
将运行模式设置为-server, 变成死循环 。 没加默认就是client模式,就是正常(可见性问题)
import java.util.concurrent.TimeUnit;
// 1、 jre/bin/server 放置hsdis动态链接库
// 测试代码 将运行模式设置为-server, 变成死循环 。 没加默认就是client模式,就是正常(可见性问题)
// 2、 通过设置JVM的参数,打印出jit编译的内容 (这里说的编译非class文件),通过可视化工具jitwatch进行查看
// -server -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -XX:+LogCompilation -XX:LogFile=jit.log
// 关闭jit优化-Djava.compiler=NONE
public class VisibilityDemo {
private volatile boolean flag = true;
public static void main(String[] args) throws InterruptedException {
VisibilityDemo demo1 = new VisibilityDemo();
Thread thread1 = new Thread(new Runnable() {
public void run() {
int i = 0;
// class -> 运行时jit编译 -> 汇编指令 -> 重排序
while (demo1.flag) { // 指令重排序
i++;
}
System.out.println(i);
}
});
thread1.start();
TimeUnit.SECONDS.sleep(2);
// 设置is为false,使上面的线程结束while循环
demo1.flag = false;
System.out.println("被置为false了.");
}
}
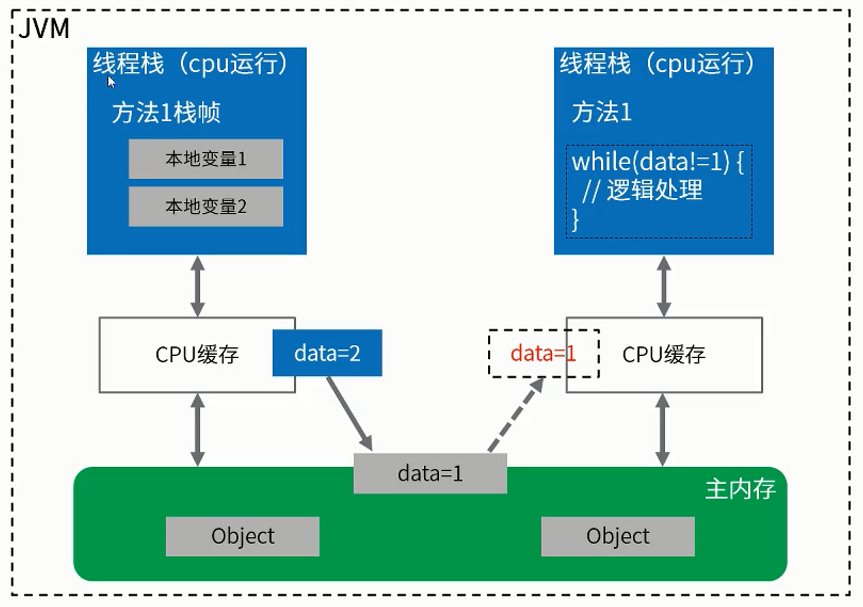
死循环可能的两个原因:
CPU缓存
CPU缓存在这里会导致线程读取的flag延迟一些变为false,但不会发生死循环
指令重排序
Java编程语言的语义允许**编译器和微处理器(JIT)**执行优化,这些优化可以与不正确的同步代码交互,从而产生看似矛盾的行为。
- 执行顺序的重排序

- 等效替换的重排序
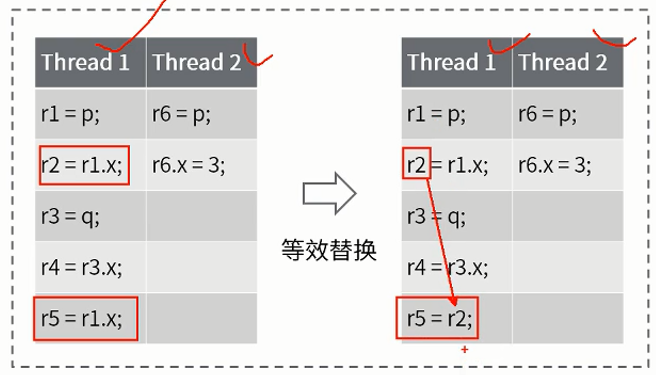
虽然有as-if- serial的原则,但是因为多CPU的情况就变得复杂了,每个cpu只能保证自己的重排序是没有问题的
真正原因
汇编层面的重排序会将while(demo1.flag)变为
if(demo1.flag){
while(true){
i++
}
}
它认为demo1.flag基本不变就是true
附: JITWatch使用
可直接参考这个操作博客
http://www.cnblogs.com/stevenczp/p/7975776.html
https://www.cnblogs.com/stevenczp/p/7978554.html
-
输出jit日志
- (windows)在jre/bin/server 放置hsdis动态链接库
- eclise、idea等工具,加上JVM参数
-server -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -XX:+LogCompilation -XX:LogFile=jit.log
-
工具安装
下载 https://github.com/AdoptOpenJDK/jitwatch -
解压 通过maven运行
mvn clean compile exec:java
-
配置jitwatch
页面选择 config, 配置要调试的项目src源码路径,和class编译路径
打开jit.log
点击start -
在分析的结果中,选中指定的类,再选择右侧的具体方法,则弹出jit编译结果
为了解决多线程的问题,提出了一种规范,就是内存模型
内存模型(Memory Model)的定义
内存模型描述程序的可能行为。
Java编程语言内存模型通过检查执行跟踪中的每个读操作,并根据某些规则检查该读操作观察到的写操作是否有效来工作。
要程序的所有执行产生的结果都可以由内存模型预测。具体的实现者任意实现,包括操作的重新排序和删除不必要的同步。
内存模型决定了在程序的每个点上可以读取什么值
比如说线程1的操作让线程2能及时看到改变,也就是说在这个点上线程2可以且必须读到它应该读取的正确的值
Shared variables共享变量
描述可以在线程之间共享的内存称为共享内存或堆内存。所有实例字段、静态字段和数组元素都存储在堆内存中。
如果至少有一个访问是写的,那么对同一个变量的两次访问(读或写)是冲突的。
这句话定义在:https://docs.oracle.com/javase/specs/jls/se8/html/jls-17.html#jis-17.4.1
线程间操作的定义
- write要写的变量以及要写的值。
- read要读的变量以及可见的写入值(由此,我们可以确定可见的值)
- lock要锁定的管程(监视器 monitor)
- unlock要解锁的管程。
- 外部操作(socket等等..)
- 启动和终止
程序顺序: 如果一个程序没有数据竞争,那么程序的所有执行看起来都是顺序一致的
本规范只涉及线程间的操作
对于同步的规则定义
同步我理解就是对一些操作约定了固定的先后顺序,且后面能看到前面的操作
- 对于监视器m的解锁与所有后续操作对于m的加锁同步
- 对 volatile变量v的写入,与所有其他线程后续对v的读同步
- 启动线程的操作与线程中的第一个操作同步
- 对于每个属性写入默认值(0, false,null)与每个线程对其进行的操作同步
- 线程T1的最后操作与线程T2发现线程T1已经结束同步(isAlive, join可以判断线程是否终结)
- 如果线程T1中断了T2,那么线程T1的中断操作与其他所有线程发现T2被中断了同步(通过抛出InterruptedException异常,或者调用Thread.interrupted或Thread.isInterrupted)
Happens- before先行发生原则
happens-before关系主要用于强调两个有冲突的动作之间的顺序,以及定义数据争用的发生时机。
具体的虚拟机实现,有必要确保以下原则的成立
- 某个线程中的每个动作都 happens-before该线程中该动作后面的动作
- 某个管程上的 unlock动作 happens-before同一个管程上后续的lock动作
- 对某个 volatile字段的写操作 happens-before每个后续对该 volatile字段的读操作
- 在某个线程对象上调用 start()方法 happens-before该启动了的线程中的任意动作
- 某个线程中的所有动作 happens-before任意其它线程成功从该线程对象上的join()中返回
- 如果某个动作a happens-before动作b,且b happens-before动作c,则有 a happens-before c
当程序包含两个没有被 happens-before关系排序的冲突访问时,就称存在数据争用
遵守了这个原则,也就意味着有些代码不能进行重排序,有些数据不能缓存!
一些实践
volatile关键字
可见性问题:让一个线程对共享变量的修改,能够及时的被其他线程看到。
根据JMM中规定的 happen before和同步原则:
对某个 volatile字段的写操作 happens-before每个后续对该 volatile字段的读操作。
对 volatile变量v的写入,与所有其他线程后续对v的读同步
要满足这些条件,所以 volatile关键字就有这些功能:
-
禁止缓存:
volatile变量的访问控制符会加个 ACC VOLATILE
https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-4.html#tjvms-4.5
-
对 volatile变量相关的指令不做重排序
fina在JMM中的处理
- final在该对象的构造函数中设置对象的字段,当线程看到该对象时,将始终看到该对象的final字段的正确构造版本。
伪代码示例:f= new finalDemo();读取到的f.x一定最新,x为final字段。而y可能是0
// 官方示例,可能会读取到y的值为0
class FinalFieldExample {
final int x;
int y;
static FinalFieldExample f;
public FinalFieldExample() {
x = 3;
y = 4;
}
static void writer() {
f = new FinalFieldExample();
}
static void reader() {
if (f != null) {
int i = f.x; // guaranteed to see 3 肯定是3
int j = f.y; // could see 0 可能看到0
}
}
}
-
如果在构造函数中设置字段后发生读取,则会看到该final字段分配的值,否则它将看到默认值;
伪代码示例:public finalDemo(){x=1;y=x;};y会等于1; -
读取该共享对象的final成员变量之前,先要读取共享对象。
伪代码示例:r = new ReferenceObj();k=r.f;这两个操作不能重排序 -
通常
static final是不可以修改的字段。然而System.in,System.out和System.err是static final字段,遗留原因,必须允许通过set方法改变,我们将这些字段称为写保护,以区别于普通final字段;
Word Tearing字节处理
一个字段或元素的更新不得与任何其他字段或元素的读取或更新交互。
特别是,分别更新字节数组的相邻元素的两个线程不得干涉或交互,也不需要同步以确保顺序一致性。
有些处理器(尤其是早期的Alphas处理器)没有提供写单个字节的功能
在这样的处理器上更新byte数组,若只是简单地读取整个内容,更新对应的字节,然后将整个内容再写回内存,将是不合法的。
这个问题有时候被称为**“字分裂 word tearing)”**,在单独更新单个字节有难度的处理器上,就需要寻求其它方式了。
基本不需要考虑这个,了解就好。
// https://docs.oracle.com/javase/specs/jls/se8/html/jls-17.html#jls-17.4
// 官方提供的示例,检查有没有WordTearing情况
public class WordTearing extends Thread {
static final int LENGTH = 8;
static final int ITERS = 1000000;
static byte[] counts = new byte[LENGTH];
static Thread[] threads = new Thread[LENGTH];
final int id;
WordTearing(int i) {
id = i;
}
public void run() {
byte v = 0;
for (int i = 0; i < ITERS; i++) {
byte v2 = counts[id];
if (v != v2) {
System.err.println("Word-Tearing found: " +
"counts[" + id + "] = " + v2 +
", should be " + v);
return;
}
v++;
counts[id] = v;
}
}
public static void main(String[] args) {
for (int i = 0; i < LENGTH; ++i)
(threads[i] = new WordTearing(i)).start();
}
}
double和long的特殊处理
虚拟机规范中,写64位的 double和long分成了两次32位值的操作
由于不是原子操作,可能导致读取到某次写操作中64位的前32位,以及另外一次写操作的后32位
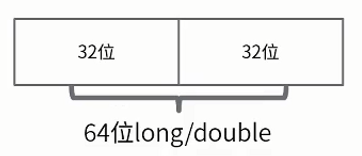
读写 volatile的long和 double总是原子的。读写引用也总是原子的
商业JⅥM不会存在这个问题,虽然规范没要求实现原子性,但是考虑到实际应用,大部分都实现了原子性。